切空间与向量空间、李群与李代数

在SLAM中,除了表达3D旋转与位移之外,我们还要对它们进行估计,因为SLAM整个过程就是在不断地估计机器人的位姿与地图。为了做这件事,需要对变换矩阵进行插值、求导、迭代等操作。例如,在经典ICP问题中,给定了两组3D点,我们要计算它们之间的变换矩阵。假设第一组的3D点为
,第二组3D点为,那我们实际要做的事情是求一个欧氏变换,使得满足:
注意这里使用了齐次坐标表示。通常,这许多个匹配过的点是通过特征匹配得到的,构成了一个超定方程。而由于噪声的存在,这个方程往往是无解的。因此我们转而计算一个最小二乘:
这时问题就来了:如果用迭代方式求解这个优化时(尽管可以不用迭代方式来求),如何求目标函数
相对于的导数呢?首先,只有6 个自由度,最好能够在一个六维空间表达它,那么相对于这个六维空间的导数(雅可比矩阵)是一个的矩阵。其次,对于乘法是封闭的,但对加法不封闭,即任意两个变换矩阵相加后并不是一个变换矩阵,这主要是因为旋转矩阵对加法是不封闭的。
出于这两个原因,我们希望有更好的数学工具帮助我们做这些事,而李群与李代数理论正好提供了这样的工具。李群与李代数广泛地用于机器人与计算机视觉领域,并在机器人动力学推导上占据重要地位。不过,由于SLAM不涉及过多的动力学推导。我们重点介绍它在SLAM中相关的几个重要的结果,而略去许多数学性质的证明。特别地,重点介绍
和这两个李群与对应的李代数。
首先,我们来讨论较为简单的三维旋转群。为了说明它的结构,首先介绍群的概念。
群
群(Group)是一种集合加上一种运算的代数结构,记作
。其中代表集合,是定义在该集合上的二元运算。那么,如果这个运算满足以下几个条件,则称为群。
读者可以记作“封结幺逆”(谐音凤姐咬你),并可以把一些常见的群放进去验证。例如整数的加法(幺元为0),去掉0后的有理数的乘法(幺元为1)。对于矩阵,可以找到一些常见的矩阵群,例如:
群结构保证了在群上的运算具有良好的性质,而群论则研究群的各种结构和性质,但我们在此不多加介绍。感兴趣的读者可以参考任意一本近世代数教材。
李群是指具有连续性质的群。并且,一般连续群上的运算还是无限可微,乃至解析的(解析比无限可微更强,它还要求任意点邻域的泰勒展开都收敛)。这个问题在20世纪初被称为希尔伯特第五问题,并已得到了解决。而李群,则指实数空间上的连续群。常见的李群包括上边提到的
,以及其他的如酉群,辛群等等。
三维旋转群
是特殊正交群在时的特例,它们可以用来描述三维空间的旋转,其元素都是 的正交且行列式为的矩阵。假设有这样一个矩阵,满足。现在,考虑它随时间发生变化,即从 变成了,仍有。在等式两边对时间求导,得到:
可以看出
是一个反对称矩阵。注意到对于任意一个的反对称矩阵,我们记它为。由于,所以它主对角线元素必为,而非对角线元素则只有三个自由度。我们可以把它对应到一个向量中去:其中
符号表示由向量转换为矩阵,反之我们也可以用符号定义由矩阵转换为向量的方式:注意到这样定义的好处之一,是它与叉积的兼容性。我们可以直接把矩阵与任意向量的乘积
写成。读者可以自行验证这个兼容性。除此之外,这样定义的向量还有一些较好的性质,后文会提到。
现在,由于
是一个反对称矩阵,我们可以找到一个三维向量与之对应。于是有:
左右各右乘
,由于为正交阵,有:可以看到,每对旋转矩阵求一次导数,只需左乘一个
矩阵即可。由于反映了的导数性质,故称它在的正切空间(tangent space)上。同时,将上式类比于一个关于的微分方程,可得:
由此我们可以引出两个概念。(1)求
的方法以及它的结构?——是对应到上的李代数;(2)如何计算?——李群与李代数间的指数/对数映射。下面我们一一加以介绍。
对于
和,李代数可定义于李群的正切空间上,描述了李群中元素局部性质,分别把它们记作小写的和。首先,给出通用的李代数的定义。
李代数由一个集合
,一个数域和一个二元运算组成。如果它们满足以下几条性质,称 为一个李代数,记作。
从表面上来看,李代数所需要的性质还是挺多的。其中二元运算被称为李括号。相比于群中的较为简单的二元运算,李括号表达了两个集合元素的差异。它不要求结合律,而满足反对称性,以及元素和自己做李括号之后为零的性质。作为类比,三维向量
上定义的叉积是一种李括号,因此构成了一个李代数。读者可以尝试将叉积的性质代入到上面四条性质中。
三维旋转群与对应的李代数
都可以生成一个反对称矩阵:
在此定义下,两个向量
的李括号为:
读者可以去验证该定义下的李括号满足上面的几条性质。由于
与反对称矩阵关系很紧密,在不引起歧义的情况下,就说的元素是3维向量或者3维反对称矩阵,不加区别:反对称矩阵有一些重要的性质,重点包括以下两条:
当
为单位向量时,进而有:以及
这两条性质读者也可以自行验证,我们在指数映射中会用到。
至此,我们已清楚了
的结构。它们是一个由三维向量组成的集合,每个向量对应到一个反对称矩阵,可以表达旋转矩阵的导数。现在来考虑是如何计算的,为此我们引入指数映射。
首先,回忆任意矩阵的指数映射。它可以写成一个泰勒展开,但是只有在收敛的情况下才会有结果,其结果仍是一个矩阵。
同样地,对
中任意一元素,我们亦可按此方式定义它的指数映射:
现在我们来仔细看看它的含义。由于
是三维向量,我们可以定义它的模长和它的方向,分别记作和(注意这里记号是有含义的,此时是一个单位长度的向量),那么按照上式,可以推出如下公式,注意中间使用了上面讲到了两个反对称矩阵的性质:
最后我们得到了一个似曾相识的式子:
回忆前一节内容,它和罗德里格斯公式(参观本系列第一篇)如出一辄。这表明,
实际上就是由所谓的旋转向量组成的空间。特别地,当转轴取一定顺序时,李代数还会变为对应的欧拉角。通过罗德里格斯公式或者指数映射,我们把 中的一个向量对应到了一个位于中的3D旋转。
反之,如果定义对数映射,我们也能把
中的元素对应到中:
其中
表示从反对称矩阵到向量的对应关系,为的逆运算。
读者可能会问,指数映射性质如何呢?它是一个双射吗?很遗憾,它只是一个满射。每个
中的元素,都可以找到中至少一个与之对应;但是可能存在多个中的元素,对应到同一个元素上。至少对于旋转角,我们知道它具有周期性。
与
的结论似乎在我们意料之中。它和我们前面讲的旋转向量与旋转矩阵很相似,而指数映射即是罗德里格斯公式。旋转向量可以视为旋转矩阵的导数,指导如何在旋转矩阵中进行微积分运算。
下面我们来介绍三维欧氏群
以及对应的李代数。有了前面的基础,我们可以直接介绍它们的结构及运算了。的结构已经在前面介绍群的时候给出:
每个变换矩阵有六个四由度,故对应的李代数位于
中:但是
不再对应到一个反对称关系,而是:可以看到,
的前三维为旋转向量,后三维为平移向量,其定义也十分的直观。该李代数对应于微分方程:
因此
那么
上的指数映射如何呢?略加推导可得:
左上角的
是我们熟知的中的元素,前文已经介绍过了。而右上角的则可整理为(设):
因此我们就得到了
的指数映射的关系。 其对数映射亦可类比推得。
最后,我们对之前介绍的李群李代数进行一个简单的小结。概而言之,李群有以下两个重要用处:
下篇中,我们将教大家用Eigen和Sophus库处理变换矩阵与李代数。敬请期待。
参考资料
[1]. Yi Ma, An Invitation to 3D Vision. 2001.
[2]. Timothy D. Barfoot, State Estimation for Robotics: A Matrix-Lie-Group Approach, 2015.
迭代最近点 (ICP) 是一种广泛使用的经典计算机视觉算法,用于二维或三维点云配准。顾名思义,它通过迭代地改进和最小化两个点云之间的空间差异或平方误差之和。这是通过估计最优刚体变换(旋转)来实现的。
迭代最近点 (ICP)算法是一种广泛应用的经典计算机视觉算法,用于二维或三维点云配准。顾名思义,它通过迭代的方式改进并最小化两个点云之间的空间差异或平方误差之和。其实现方式是估计最优的刚体变换(旋转和平移)矩阵,从而更好地将“源”或参考点集与同一坐标系![[R \ | \ t]](https://learnopencv.com/wp-content/ql-cache/quicklatex.com-93865d187d73fe2a9972efad7dce2498_l3.png) 中的“目标”点集对齐。ICP 算法在医学成像、三维空间建模、即时定位与地图构建 (SLAM)、自动驾驶汽车和机器人等领域有着广泛的应用。
中的“目标”点集对齐。ICP 算法在医学成像、三维空间建模、即时定位与地图构建 (SLAM)、自动驾驶汽车和机器人等领域有着广泛的应用。
 算法详解 – LearnOpenCV")
ICP 最早由 Besl 和 McKay 正式提出,其概念可以追溯到 1992 年。自那时以来,ICP 已经发展了很多,衍生出了许多变体,并进行了显著的改进,主要针对鲁棒的对应匹配、加权误差度量和最近邻搜索的加速结构。
在本文中,我们将概述 ICP、其流程、变体和实际应用案例,并提供一个使用 Open3D 的演示示例。
如果您是刚刚开始接触 3D 计算机视觉的人,我们的系列文章将指导您了解3D 视觉和重建的基础知识。

点云本质上是三维坐标系中的一组顶点,表示为 P = {p_1, p_2, …, p_N} 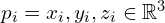 。为了构建物体(例如雕像)的三维重建,我们首先需要从多个角度拍摄场景。点云的来源可以是激光雷达、RGB 相机或立体相机,每次扫描都会生成一个独立的点云。
。为了构建物体(例如雕像)的三维重建,我们首先需要从多个角度拍摄场景。点云的来源可以是激光雷达、RGB 相机或立体相机,每次扫描都会生成一个独立的点云。
难点在于如何将从不同视角或不同时间间隔拍摄的物体多次扫描的特征组合成一个连贯的整体,避免出现间隙、变形或异常值。为了从中创建完整的几何体,我们需要将它们精细地拼接在一起。在同一个坐标系中,找到使源点云与目标点云对齐的精确旋转和平移的过程称为配准。

它首先对变换进行初始猜测,然后逐步改进,直到满足收敛准则。ICP 的直观思想是,如果我们知道源点云和目标点云之间的对应点,那么在数学上找到最佳变换就非常简单。另一方面,如果我们知道正确的变换,那么找到对应点也很容易,而且它们会完美对齐。但我们两者都不知道,因此 ICP 会在估计对应点和基于初始对应点估计变换之间交替进行。如果两个点云来自同一源,我们就无需考虑缩放问题。

尽管 ICP 的概念很简单,但它的有效性取决于初始化质量、误差度量的选择以及异常值剔除策略等因素。

标准ICP算法包含以下步骤:

ICP 不是从零开始;它从对变换的初始估计开始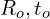 ,大致将源云
,大致将源云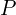 与目标云对齐
与目标云对齐 。
。
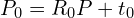
这里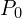 展示的是应用初始变换后的源云。初始猜测的质量至关重要;糟糕的初始化会导致ICP收敛到错误的算法(局部最小值),甚至根本无法收敛。
展示的是应用初始变换后的源云。初始猜测的质量至关重要;糟糕的初始化会导致ICP收敛到错误的算法(局部最小值),甚至根本无法收敛。
最初的猜测可能来自:
 。
。 对于当前迭代变换后的源点云中的每个点,找到目标点云中
对于当前迭代变换后的源点云中的每个点,找到目标点云中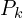 距离它最近的点。“最近”通常由欧氏距离定义。此步骤建立了一组相关的对应点对。然而,为点云中的每个点找到匹配点对的计算量非常大。为了克服这一瓶颈,最常用的方法是在静态目标点云上构建kd 树。kd 树递归地划分三维空间,从而实现高效的最近邻搜索。这通过从源点云中找到查询点的最近邻来缩小搜索空间,从而显著加快了处理速度。
距离它最近的点。“最近”通常由欧氏距离定义。此步骤建立了一组相关的对应点对。然而,为点云中的每个点找到匹配点对的计算量非常大。为了克服这一瓶颈,最常用的方法是在静态目标点云上构建kd 树。kd 树递归地划分三维空间,从而实现高效的最近邻搜索。这通过从源点云中找到查询点的最近邻来缩小搜索空间,从而显著加快了处理速度。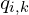
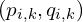
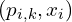 给定上一步找到的匹配点对集合,该算法计算
给定上一步找到的匹配点对集合,该算法计算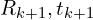 使这些点对最佳对齐的刚体变换()。通过最小化变换后的源点与其对应目标点之间的平方欧氏距离之和。
使这些点对最佳对齐的刚体变换()。通过最小化变换后的源点与其对应目标点之间的平方欧氏距离之和。
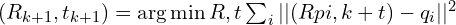
该优化问题具有闭式解。寻找最优旋转 和平移的常用且稳健的方法
和平移的常用且稳健的方法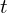 是使用奇异值分解 (SVD)。首先计算对应源点 (
是使用奇异值分解 (SVD)。首先计算对应源点 ( 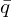 ) 的质心(平均位置)。然后计算质心点:
) 的质心(平均位置)。然后计算质心点: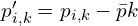 和
和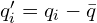 。
。
交叉方差矩阵是将这些中心化后的对应对的外积相加而得到的。
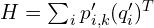
对该矩阵应用奇异值分解 (SVD)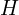 可得到三个矩阵,
可得到三个矩阵,
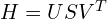 。
。
这里,
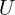 并且
并且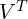 是表示旋转/反射的正交矩阵
是表示旋转/反射的正交矩阵 是一个对角矩阵,对角线上只有一个值。
是一个对角矩阵,对角线上只有一个值。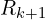 然后计算最优旋转矩阵
然后计算最优旋转矩阵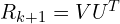 。通常需要进行特殊检查:如果的行列式为 -1(表示反射而非正确的旋转),则
。通常需要进行特殊检查:如果的行列式为 -1(表示反射而非正确的旋转),则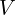 通常需要先将最后一列的符号取反,然后再重新计算,以确保它是一个有效的旋转矩阵。一旦找到最优旋转,就可以使用质心轻松计算最优平移。
通常需要先将最后一列的符号取反,然后再重新计算,以确保它是一个有效的旋转矩阵。一旦找到最优旋转,就可以使用质心轻松计算最优平移。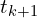
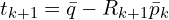
然后应用新计算的变换来更新源点云。通常,变换是相对于原始源点云累积的,而不是迭代地变换点本身,以避免潜在的漂移。
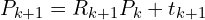
该算法会检查是否满足终止条件。常见的收敛准则包括:
如果满足收敛准则,算法终止并输出最终变换()。否则,递增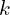 (即
(即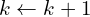 ),并返回步骤 2。找到两个云之间最佳的匹配,并找到对应关系。基于此,尝试优化平移和旋转。
),并返回步骤 2。找到两个云之间最佳的匹配,并找到对应关系。基于此,尝试优化平移和旋转。


虽然流程看起来很简单,但有几个因素会严重影响 ICP 在现实世界中的有效性:

基本的ICP算法(通常称为点对点ICP算法)启发了许多旨在提高收敛速度和精度的变体:

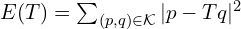
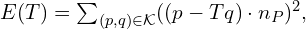


首先,我们将通过 Open3D 示例可视化 ICP。然后,我们将用 Python 实现一个非常简单的 ICP 版本,以理解其底层机制。
1
|
!pip install open3d |
导入依赖项
1
2
3
4
|
import numpy as npimport matplotlib.pyplot as pltimport open3d as o3dimport copy |
导入数据集
我们将从 Open3D ICP 演示数据集中加载两个示例点云(源点云和目标点云),每个点云都代表从不同视角捕获的房间的 3D 扫描。
1
2
3
4
5
6
|
# Read source and target PCDdemo_pcds = o3d.data.DemoICPPointClouds()source = o3d.io.read_point_cloud(demo_pcds.paths[0]) # PointCloud with 191397 points.#source.dimension( ) -> 3target = o3d.io.read_point_cloud(demo_pcds.paths[1]) # PointCloud with 137833 points.#target.dimension( ) -> 3 |

注册前可视化输入
1
2
3
4
5
6
7
8
9
10
11
|
o3d.visualization.draw_plotly([source], zoom=0.455, front=[-0.4999, -0.1659, -0.8499], lookat=[2.1813, 2.0619, 2.0999], up=[0.1204, -0.9852,Q 0.1215])o3d.visualization.draw_plotly([target], zoom=0.455, front=[-0.4999, -0.1659, -0.8499], lookat=[2.1813, 2.0619, 2.0999], up=[0.1204, -0.9852, 0.1215]) |

以下函数可视化了经过粗略初始对齐变换后的目标点云和源点云。目标点云和源点云分别用青色和黄色表示。两个点云重叠越多、越紧密,对齐结果就越好。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
def draw_registration_result(source, target, transformation): source_temp = copy.deepcopy(source) target_temp = copy.deepcopy(target) source_temp.paint_uniform_color([1, 0.0706, 0]) target_temp.paint_uniform_color([0, 0.651, 0.929]) source_temp.transform(transformation) o3d.visualization.draw_plotly([source_temp, target_temp])# *** Initial Transformation ***trans_init = np.asarray([[0.862, 0.011, -0.507, 0.5], [-0.139, 0.967, -0.215, 0.7], [0.487, 0.255, 0.835, -1.4], [0.0, 0.0, 0.0, 1.0]])draw_registration_result(source, target, trans_init) |
该函数 evaluate_registration 计算两个主要指标:
fitness该指标衡量重叠区域(内点对应点数/源点数)。数值越高越好。inlier_rmse它衡量所有内点对应关系的均方根误差 (RMSE)。数值越低越好。默认情况下, registration_icp 程序会运行直至收敛或达到最大迭代次数(默认为 30 次)。可以更改此设置以允许更多计算时间并进一步提高结果。
1
2
3
4
5
6
7
8
9
|
threshold = 0.02print("Initial Alignment")evaluation = o3d.pipelines.registration.evaluate_registration( source, target, threshold, trans_init)print(evaluation)"""Initial alignmentRegistrationResult with fitness=2.740900e-02, inlier_rmse=1.259521e-02, and correspondence_set size of 5246Access transformation to get result.""" |
该类 TransformationEstimationPointToPoint 提供用于计算点对点ICP目标函数的残差和雅可比矩阵的函数。该函数 `registration_icp` 以残差和雅可比矩阵作为参数,并运行点对点ICP算法以获得结果。
点对点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# ******* Point-to-Point *********threshold = 0.02print("Apply point-to-point ICP")reg_p2p = o2d.pipelines.registration.registration_icp( source, target, threshold, trans_init, o3d.pipelines.registration.TransformationEstimationPointToPoint())print(reg_p2p)print("Transformation is:")print(reg_p2p.transformation)draw_registration_result(source, target, reg_p2p.transformation)"""Apply point-to-point ICPRegistrationResult with fitness=3.132755e-02, inlier_rmse=1.168464e-02, and correspondence_set size of 5996Access transformation to get result.Transformation is:[[ 0.86481662 0.0378514 -0.50084398 0.42597758] [-0.15157681 0.97072361 -0.18799414 0.66535821] [ 0.47817432 0.23769297 0.84517011 -1.35537445] [ 0. 0. 0. 1. ]]""" |
得分 fitness 从 0.174723 增加到 0.372450。 inlier_rmse 从 0.011771 减少到 0.007760。

点到平面
点到面 ICP 算法使用点法线。在本教程中,我们将从文件中加载法线。如果未提供法线,则可以使用顶点法线估计来计算。`registration_icp` 函数会使用不同的参数调用 TransformationEstimationPointToPlane。该类内部实现了用于计算点到面 ICP 目标函数的残差矩阵和雅可比矩阵的函数。
1
2
3
4
5
6
7
8
9
|
threshold=0.02print("Apply point-to-point ICP")reg_p2p = o3d.pipelines.registration.registration_icp( source, target, threshold, trans_init, o3d.pipelines.registration.TransformationEstimationPointToPoint())print(reg_p2p)print("Transformation is:")print(reg_p2p.transformation)draw_registration_result(source, target, reg_p2p.transformation) |
点到平面 ICP 在 30 次迭代内达到紧密对齐( fitness 得分分别为 0.620972 和 inlier_rmse 0.006581)。

将两个原本相同但经过齐次变换的正弦点云对齐。ICP算法通过最小化两个点云之间的距离,逐步使它们对齐。
1
2
3
4
|
import numpy as npfrom sklearn.neighbors import NearestNeighborsimport matplotlib.pyplot as pltimport matplotlib.animation as animation |
m函数best_fit_transfor实现了一种最小二乘最佳拟合变换算法,用于映射两个点云(A 和 B)之间的匹配点(对应关系)。它计算将 A 变换到 B 所需的旋转矩阵、平移向量和齐次变换矩阵。
步骤:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
def best_fit_transform(A, B): """ Calculates the best-fit transform that maps points A onto points B. Input: A: Nxm numpy array of source points B: Nxm numpy array of destination points Output: T: (m+1)x(m+1) homogeneous transformation matrix """ assert A.shape == B.shape m = A.shape[1] centroid_A = np.mean(A, axis=0) centroid_B = np.mean(B, axis=0) AA = A - centroid_A BB = B - centroid_B H = np.dot(AA.T, BB) U, S, Vt = np.linalg.svd(H) R = np.dot(Vt.T, U.T) if np.linalg.det(R) < 0: Vt[m-1,:] *= -1 R = np.dot(Vt.T, U.T) t = centroid_B.reshape(-1,1) - np.dot(R, centroid_A.reshape(-1,1)) T = np.eye(m+1) T[:m, :m] = R T[:m, -1] = t.ravel() return T |
接下来,我们需要找到目标点云和源点云之间的最近邻点。该函数nearest_neighbor接受两个输入 src 和 dst,并使用 kd 树返回 src 中每个点到 dst 中最近邻点的欧氏距离和索引。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
def nearest_neighbor(src, dst): ''' Find the nearest (Euclidean) neighbor in dst for each point in src Input: src: Nxm array of points dst: Nxm array of points Output: distances: Euclidean distances of the nearest neighbor indices: dst indices of the nearest neighbor ''' # Ensure shapes are compatible for KNN, although they don't strictly need to be identical N assert src.shape[1] == dst.shape[1] neigh = NearestNeighbors(n_neighbors=1) neigh.fit(dst) distances, indices = neigh.kneighbors(src, return_distance=True) return distances.ravel(), indices.ravel() |
以下函数实现了ICP算法,迭代地更新更新后的A点和B点之间的变换关系。迭代过程持续进行,直到当前迭代和前一次迭代之间最近点距离的平均误差之差小于指定的容差值,或者达到最大迭代次数为止。输出结果是最终的齐次变换矩阵,T_final该矩阵将A点映射到B点,直至收敛。
为了可视化所有步骤的收敛过程,我们还需要存储中间步骤。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
|
# --- Modified ICP function to store history ---def iterative_closest_point_visual(A, B, max_iterations=20, tolerance=0.001): ''' The Iterative Closest Point method: finds best-fit transform that maps points A on to points B. Stores intermediate results for visualization. Input: A: Nxm numpy array of source points B: Nxm numpy array of destination points max_iterations: exit algorithm after max_iterations tolerance: convergence criteria Output: T_final: final homogeneous transformation that maps A on to B intermediate_A: List containing A transformed at each iteration (N x m arrays) intermediate_errors: List containing the mean error at each iteration i: number of iterations to converge ''' # Check dimensions # Allow N to differ, but dimensions (m) must match assert A.shape[1] == B.shape[1] # get number of dimensions m = A.shape[1] # --- Store History --- intermediate_A = [np.copy(A)] # Store initial state intermediate_errors = [] # --- Store History --- # make points homogeneous, copy them to maintain the originals # Use np.copy() for src to allow modification without affecting original A src_h = np.ones((m+1, A.shape[0])) src_h[:m, :] = np.copy(A.T) # Target points (B) remain fixed, use non-homogeneous for KNN dst = np.copy(B) # Non-homogeneous target points for KNN prev_error = float('inf') # Initialize with infinity T_cumulative = np.identity(m+1) # To accumulate transformations correctly for i in range(max_iterations): # Current source points (non-homogeneous) current_src = src_h[:m, :].T # find the nearest neighbors between the current source and destination points distances, indices = nearest_neighbor(current_src, dst) # compute the transformation between the current source and nearest destination points # Use the subset of B (dst) corresponding to the nearest neighbors found T_step = best_fit_transform(current_src, dst[indices, :]) # update the current source points *in homogeneous coordinates* src_h = np.dot(T_step, src_h) # --- Store History --- intermediate_A.append(src_h[:m, :].T) # Store transformed A for this iteration # --- Store History --- # check error (stop if error is less than specified tolerance) mean_error = np.mean(distances) intermediate_errors.append(mean_error) # Store error for this iteration # Use absolute difference check for convergence if np.abs(prev_error - mean_error) < tolerance: print(f"Converged at iteration {i+1} with error difference {np.abs(prev_error - mean_error)}") break prev_error = mean_error # Accumulate transformation T_cumulative = np.dot(T_step, T_cumulative) # Calculate the *final* transformation from the *original* A to the *final* src position # This accounts for the accumulated transform T_final = best_fit_transform(A, src_h[:m, :].T) # If loop finished due to max_iterations without converging based on tolerance if i == max_iterations - 1: print(f"Reached max iterations ({max_iterations})") return T_final, intermediate_A, intermediate_errors, i + 1 # Return i+1 for actual count |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
# Define two sets of points A and B (same as your example)t = np.linspace(0, 2*np.pi, 10)A = np.column_stack((t, np.sin(t)))# Define the rotation angletheta = np.radians(30)c, s = np.cos(theta), np.sin(theta)rotation_matrix = np.array(((c, -s), (s, c)))# Define translation vectortranslation_vector = np.array([[2, 0]])# Apply the transformation and add randomness to get Bnp.random.seed(42) # for reproducible randomnessrandomness = 0.3 * np.random.rand(10, 2)B = np.dot(rotation_matrix, A.T).T + translation_vector + randomness# --- Run ICP and get history ---max_iter = 20tolerance = 0.0001 # Lower tolerance for smoother convergence potentiallyT_final, history_A, history_error, iters = icp.iterative_closest_point_visual(A, B, max_iterations=max_iter, tolerance=tolerance)print(f'Converged/Stopped after {iters} iterations.')print(f'Final Mean Error: {history_error[-1]:.4f}')print('Final Transformation:')print(np.round(T_final, 3)) |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
# --- Create Animation ---fig, ax = plt.subplots()# Plot target points (static)ax.scatter(B[:, 0], B[:, 1], color='blue', label='Target B', marker='x')# Plot initial source pointsscatter_A = ax.scatter(history_A[0][:, 0], history_A[0][:, 1], color='red', label='Source A (moving)')title = ax.set_title(f'Iteration 0, Mean Error: N/A')ax.legend()ax.set_xlabel("X")ax.set_ylabel("Y")ax.grid(True)ax.axis('equal') # Important for visualizing rotations correctly# Determine plot limits based on all points across all iterationsall_points = np.vstack([B] + history_A)min_vals = np.min(all_points, axis=0)max_vals = np.max(all_points, axis=0)range_vals = max_vals - min_valsmargin = 0.1 * range_vals # Add 10% marginax.set_xlim(min_vals[0] - margin[0], max_vals[0] + margin[0])ax.set_ylim(min_vals[1] - margin[1], max_vals[1] + margin[1])# Animation update functiondef update(frame): # Update source points position scatter_A.set_offsets(history_A[frame]) # Update title error_str = f"{history_error[frame-1]:.4f}" if frame > 0 else "N/A" # Error calculated *after* step title.set_text(f'Iteration {frame}, Mean Error: {error_str}') # Return the artists that were modified return scatter_A, title,# Create the animation# Number of frames is number of states stored (initial + iterations)# Interval is milliseconds between frames (e.g., 500ms = 0.5s)ani = animation.FuncAnimation(fig, update, frames=len(history_A), interval=500, blit=True, repeat=False)# Display the final plot (optional, animation already shows it)plt.figure()plt.scatter(history_A[-1][:, 0], history_A[-1][:, 1], color='red', label='Final A')plt.scatter(B[:, 0], B[:, 1], color='blue', label='Target B', marker='x')plt.legend()plt.title(f"Final Alignment after {iters} iterations")plt.xlabel("X")plt.ylabel("Y")plt.grid(True)plt.axis('equal')plt.show() |
“只要方法得当,传统的ICP依然强大。”
我们深入探讨了迭代最近点算法(ICP),并理解了其数学公式如何转化为Python代码。虽然基于深度学习的方法和复杂的配准技术在复杂场景下具有优势,但ICP的核心原理提供了一种简单有效的途径,在某些特定场景下甚至优于最先进的SLAM算法。这凸显了经典的计算机视觉算法在许多应用中仍然具有重要意义,并且是基础架构。
希望您觉得这篇文章有趣。欢迎通过我们的社交媒体账号分享您的反馈意见。
这篇文章旨在提供一个具体的例子,让机器人专家们对李代数及其在机器人领域的应用有所了解。我最初学习李代数时,感觉网上关于李代数的解释过于浅显,缺乏清晰易懂的数学细节。希望这篇文章能够弥合这种差距。让我们开始吧。
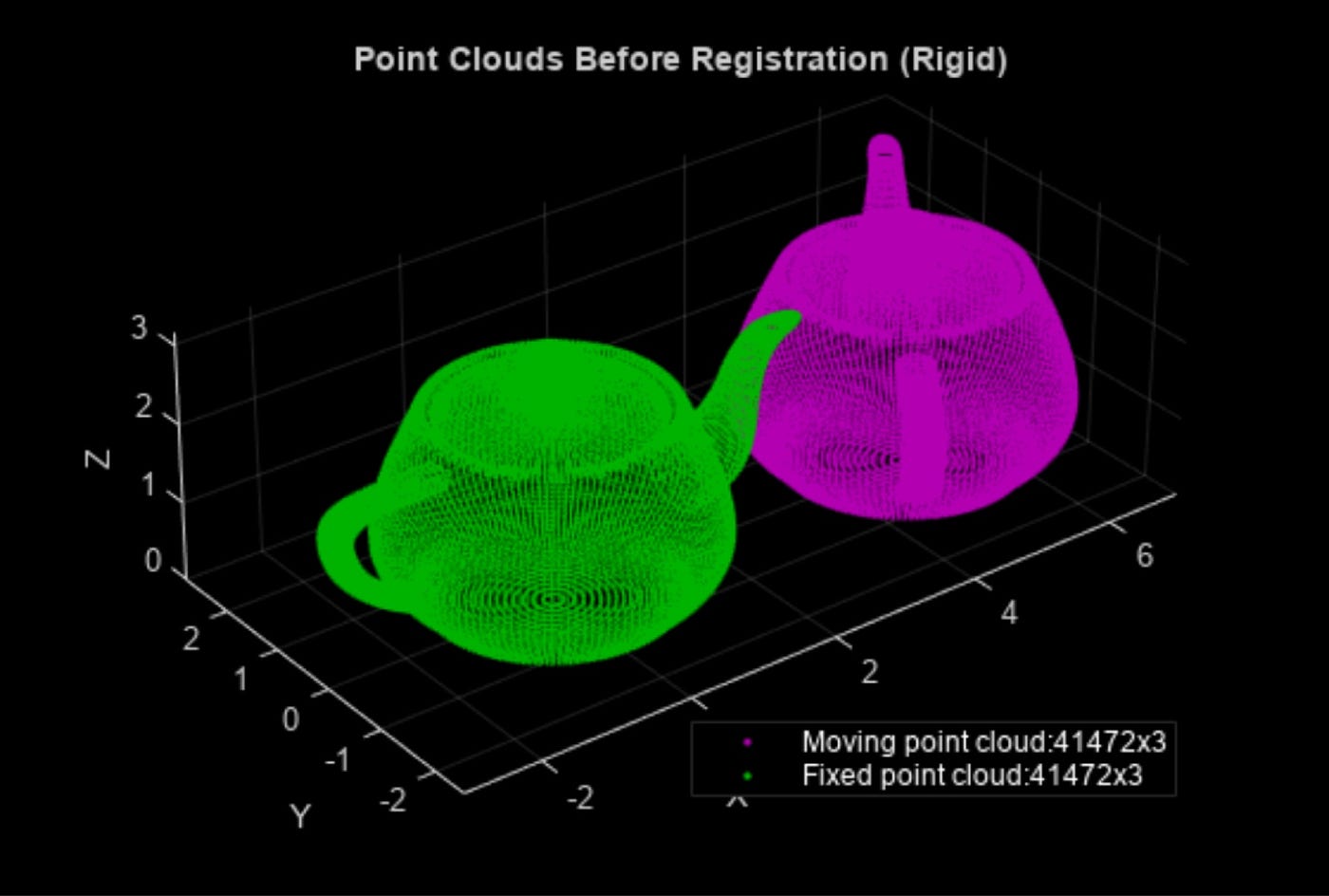
本文仅考虑迭代最近点算法(Iterative Closest Point,ICP)。为简单起见,我们仅讨论旋转问题,不涉及平移。ICP 算法通过最小化对应点之间的距离来对齐两个点云。在本例中,它优化旋转矩阵 R 以减小平方差之和。
如同许多工程实践一样,我们希望使用一阶泰勒级数展开来近似函数,展开平方项,对 ΔR 求导,令导数为零,最终将问题表示为一个正规方程。求解该方程即可得到 ΔR,进而可以用它更新 R。ICP 问题正是通过多次重复此过程(假设收敛)来求解的,因此得名“迭代”。
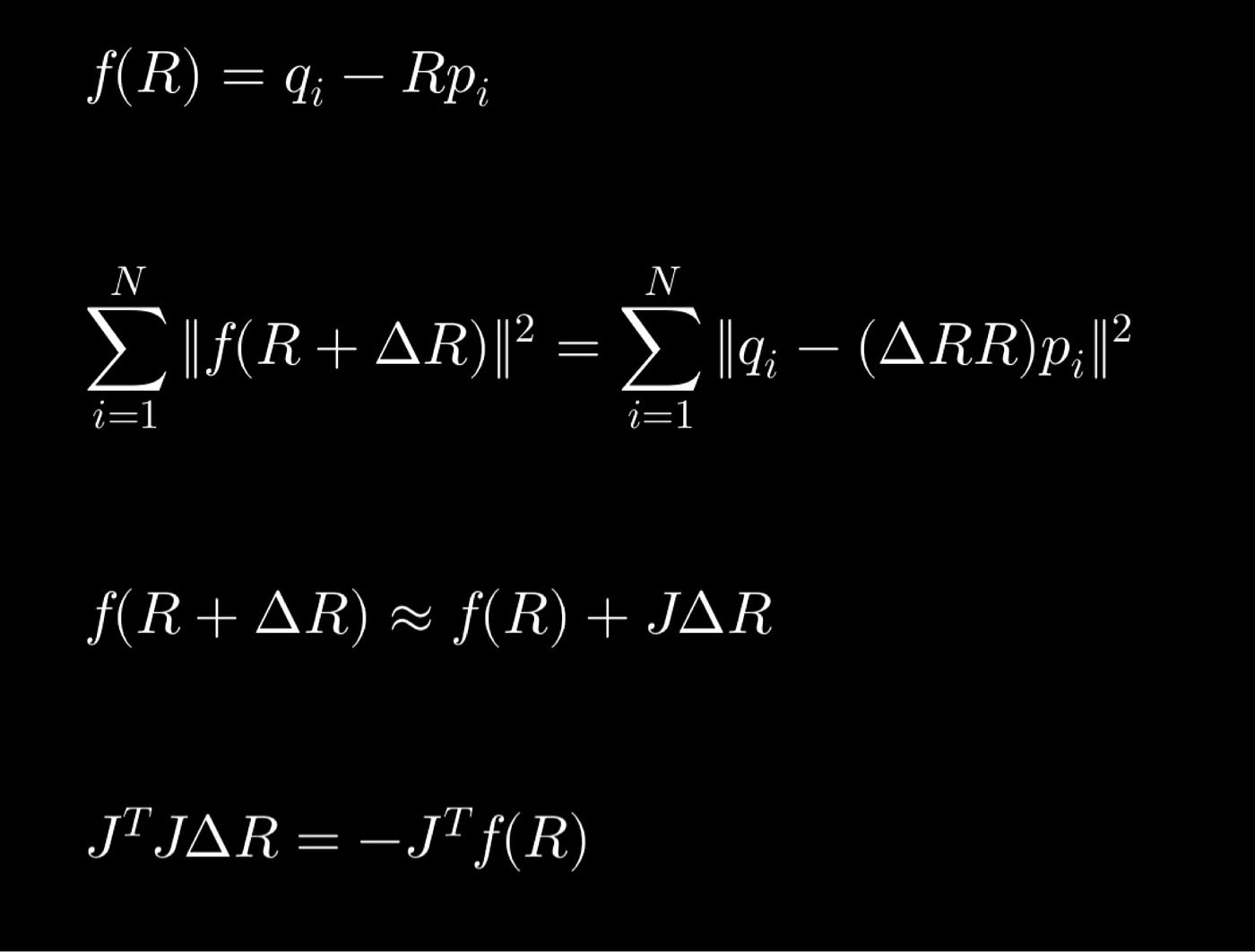
然而,这里我们遇到了一个问题。如果我们把3x3旋转矩阵看作9个独立元素并求解,结果很可能不是旋转矩阵。旋转矩阵需要满足诸如det(R)=1和RR^T=I单位矩阵之类的约束条件。而如何在满足这些约束条件的前提下建立一个可微的代价函数,这一点并不明显。
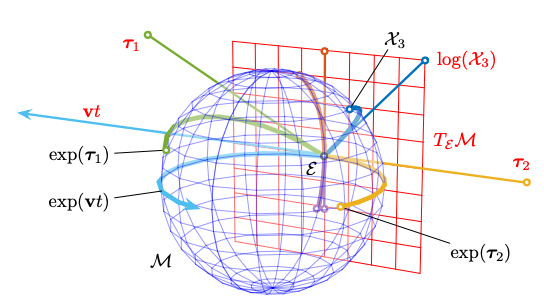
这就是李群和李代数发挥作用的地方。旋转构造属于李群,李群是一个具有流形结构的连续变换群。流形是一个光滑的广义曲面,可以局部地用线性空间(也称为切空间)逼近。这类似于地球的曲面可以局部地逼近为一个平面;虽然地球是一个三维球体,但其表面在任何一点都感觉像是一个二维平面。
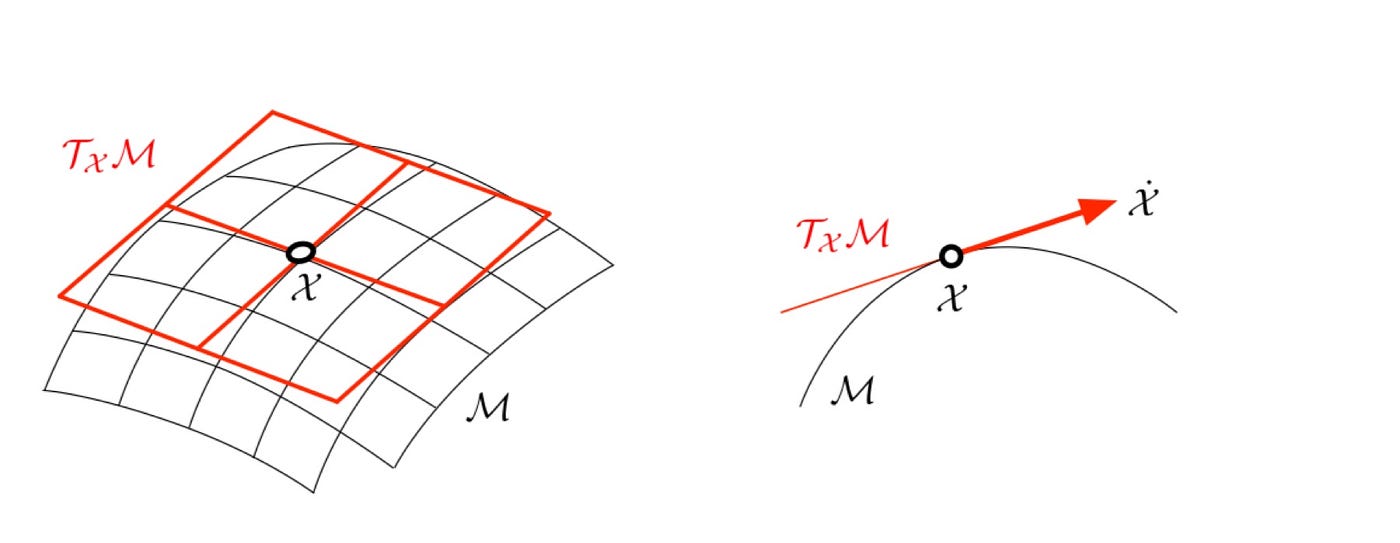
关键在于切空间是线性的,而李代数能够局部地捕捉这种线性结构。如果我们能够以某种方式用李代数(具有3个自由度)来表达我们的目标函数,从而将其置于线性空间中,我们就可以(再次)构建一个优化问题,而无需考虑应用于旋转矩阵的约束。

这里值得稍作停顿。为什么我们用不同的数学结构来表达最初的问题后,就不再需要担心旋转矩阵的约束了呢?这是因为这些约束是由流形或李群本身施加的。
想象一下等离子体被限制在球面上,例如地球磁层上的带电粒子。如果我们想求解它们的“流体动力学”,就无法在开放域(三维空间)中进行求解。解被限制在三维空间中的一个二维曲面上。因此,如果我们用 S²(代表球面的流形)来表达这个问题,那么问题本身就是有约束的。
类似地,我们可以想象三维旋转被限制在一个具有更复杂结构的三维几何曲面(位于九维空间中)上——即李群——形式上称为特殊正交群SO(3)。该群不仅具有流形结构,而且还具有一个光滑的群运算,该运算定义了旋转如何组合。

我们之前没有讨论过的一点是,李代数被定义为李群单位元处的切空间。了解这一点可以简化我们的方程,如下所示:
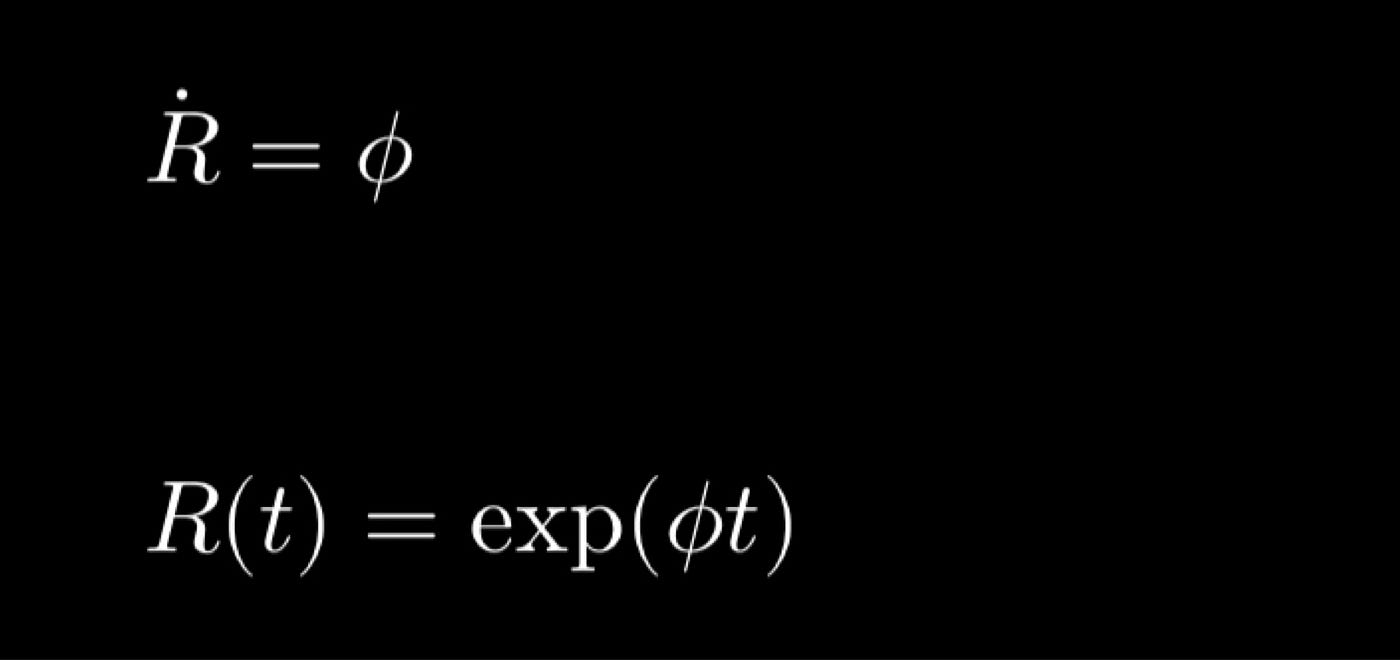
由于 R 属于李群 SO(3),其导数 Ṙ 位于 R 的切空间中。由此我们可以推断,phi 是属于李代数 so(3) 的斜对称矩阵,即 SO(3) 在单位元处的切空间。
还记得我们希望用 3x1 向量而不是 3x3 矩阵来表示旋转(及其增量)吗?不难看出,3x1 向量和相应的反对称矩阵之间存在一一对应的关系。

我们可以将向量到反对称矩阵的转换定义为帽子符号 (∧),反向转换定义为三角符号 (∨)。那么我们知道函数 g() 具有 exp(. ∧) 的形式,它将一个 3x1 的向量映射到一个 3x3 的旋转矩阵。
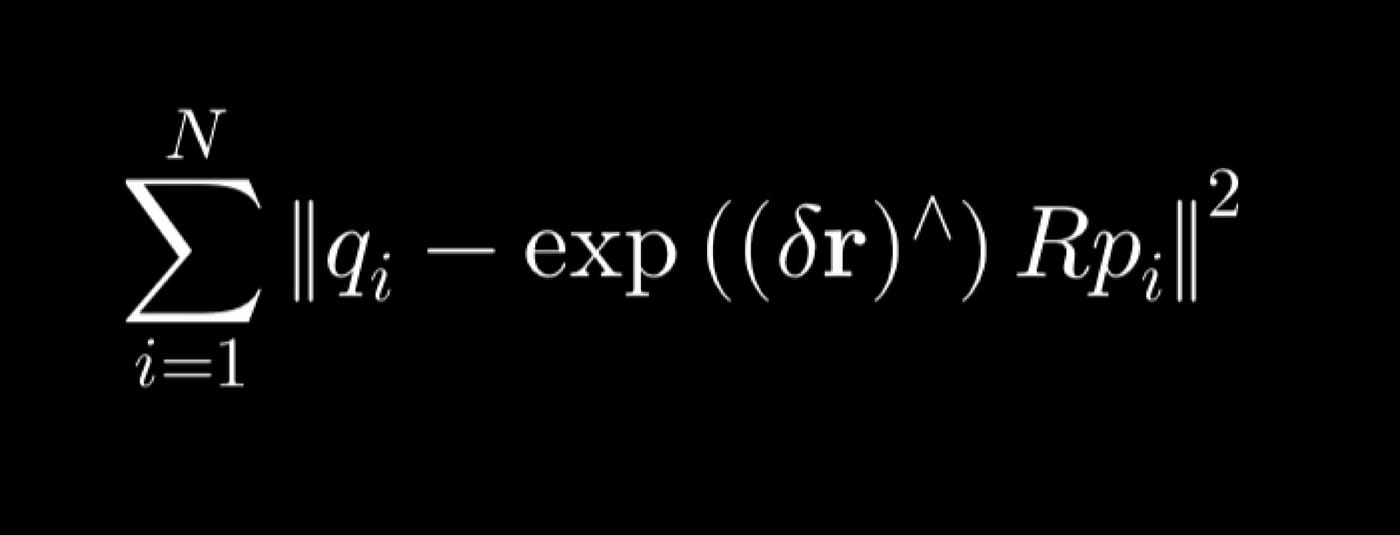
记住矩阵指数 exp(A) 可以近似为 I + A,并回想 a^b = -a^b,其中 a^b 可以理解为两个 3x1 向量 a 和 b 的叉积。然后我们最终可以将代价函数表示为 f(R + δr) ≈ f(R) + Jδr,其中 J 等于 [Rp]^。在求解 δr 的正规方程后,我们可以更新 R ← exp(δr) R。
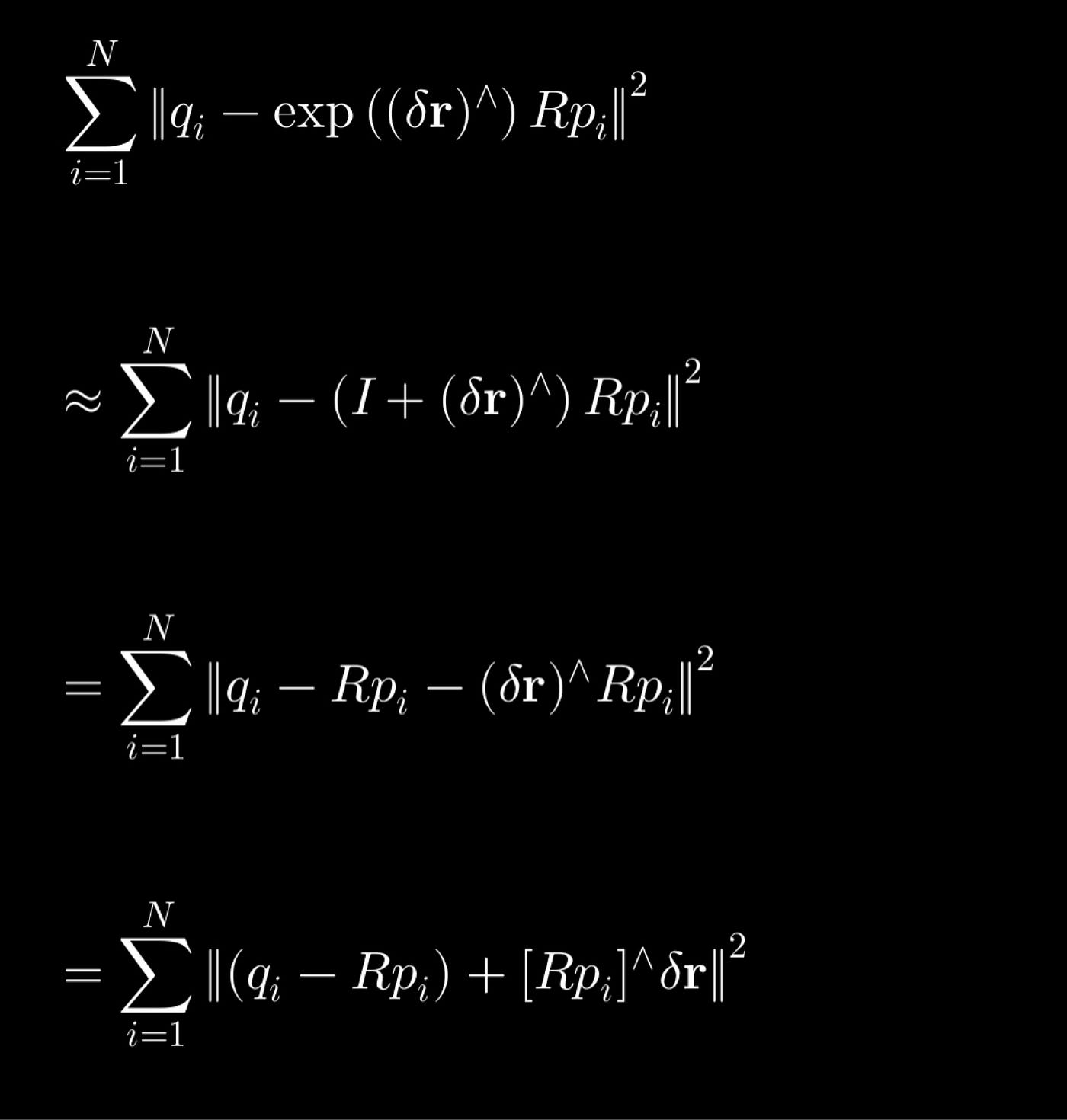
本文到此结束。当然,还有其他更直观的方法可以解决ICP问题。但在诸如扩展卡尔曼滤波(EKF)或同步定位与建图(SLAM)等应用中,由于涉及将三维旋转作为状态向量,推导雅可比矩阵并用李代数表示协方差会很有帮助。
李群既是流形又是群,其群运算——乘法和逆运算——是光滑(无限可微)映射。换句话说,它无缝地融合了代数结构(来自群论)和几何结构(来自流形)。这种几何框架自然地与线性代数和工程数学相结合,为分析连续变换(例如旋转和刚体运动)提供了强大的工具。
如需进一步阅读,我推荐阅读“用于机器人状态估计的微观李理论”。